
*爬取结果
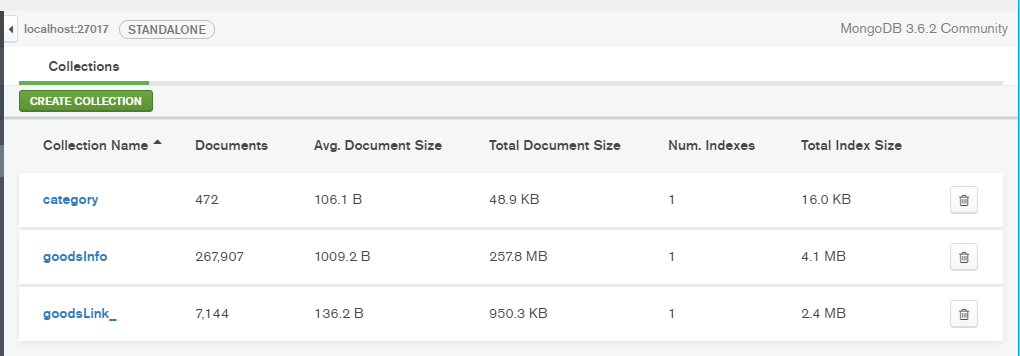
1.获取二手商品分类Link
import requests
from bs4 import BeautifulSoup
import pymongo
client = pymongo.MongoClient('localhost',27017)
db_project = client['58project']
cateLinks = db_project['cateLinks']
def getCateLink():
baseUrl = 'http://sz.58.com/sale.shtml'
wbData = requests.get(baseUrl)
soup = BeautifulSoup(wbData.text,'lxml')
links = soup.select('ul.ym-submnu > li > b > a')
return list(set('http://sz.58.com{}'.format(link.get('href')) for link in links))
links = getCateLink()
for link in links:
cateLinks.insert_one({'cateLinks':link})
2.获取二手商品Link
import requests
from bs4 import BeautifulSoup
import time
import random
import pymongo
import re
client = pymongo.MongoClient('localhost', 27017)
db_project = client['58project']
goodsLinksSheet = db_project['new_goodsLinks']
errorNote = db_project['errorNote']
def getGoodsLink(cateLink, page):
url = '{}pn{}/'.format(cateLink, str(page))
wbData = requests.get(url)
if not wbData:
errorNote.insert_one({'cateLink':cateLink,'page':page})
return False
soup = BeautifulSoup(wbData.text, 'lxml')
if not soup.find('div', 'noinfotishi'):
time.sleep(random.randrange(2, 4))
for link in soup.find_all('a', class_='t', href=re.compile('zhuanzhuan.58')):
goodsLink = link.get('href').split('?')[0]
goodsLinksSheet.insert_one({'goodsLink': goodsLink})
print(cateLink,'|',page,'|', goodsLink)
else:
return False
3.获取二手商品详情信息并逐条插入MongoDB
import requests
from bs4 import BeautifulSoup
import time
from getMongoData import getData
import pymongo
import random
import re
client = pymongo.MongoClient('localhost', 27017)
projectDb = client['58project']
goodsInfo = projectDb['goodsInfo']
fiter = projectDb['fiter']
def getGoodsinfo(goodsLink):
if goodsInfo.find({'goodsLink': goodsLink}).count() == 0:
time.sleep(random.randrange(3, 5))
wbData = requests.get(goodsLink)
if wbData.status_code == 200:
soup = BeautifulSoup(wbData.text, 'lxml')
if soup.find('p',class_ = 'personal_name'):
name = soup.find('p', class_='personal_name').get_text() if soup.find('p', class_='personal_name') else None
join58Age = re.sub('\D', '', soup.find('p', class_='personal_chengjiu').get_text()) if soup.find('p',class_='personal_chengjiu') else 0
orderNum = soup.find('span', class_='numdeal').get_text() if soup.find('span', class_='numdeal') else 0
title = soup.find('h1', class_='info_titile').get_text() if soup.find('h1', class_='info_titile') else None
viewTimes = re.sub('\D', '', soup.find('span', class_='look_time').get_text()) if soup.find('span', class_='look_time') else 0
price = soup.select('.price_now i')[0].get_text() if soup.select('.price_now i') else 0
address = soup.select('.palce_li i')[0].get_text().split('-') if soup.select('.palce_li i') else None
bodyPic = list(map(lambda x: x.get('src'), soup.select('div.boby_pic > img'))) if soup.select(
'div.boby_pic > img') else None
describe = soup.select('.baby_kuang p')[0].get_text() if soup.select('.baby_kuang p') else None
headImgLink = soup.select('.personal_touxiang img')[0].get('src') if soup.select('.personal_touxiang img') else None
bodyPic = '|'.join(bodyPic) if bodyPic != None else None
data = {
'name': name,
'join58Age': int(join58Age) if join58Age != '' else 0,
'orderNum': int(orderNum),
'title': title,
'viewTimes': int(viewTimes) if viewTimes != '' else 0,
'price': int(price) if price.isdigit() else 0,
'address': address,
'describe': describe,
'headImgLink': headImgLink,
'bodyPic': bodyPic,
'goodsLink': goodsLink
}
goodsInfo.insert_one(data)
fiter.insert_one({'url': goodsLink})
print(data, '\n')
else:
print(goodsLink)
def deleteData():
res = goodsInfo.delete_many({'name': ''})
print(res)
def getLineNum():
# goodsLink = getData('new_goodsLinks')
# res = set(map(lambda x:x['goodsLink'],goodsLink))
res = goodsInfo.distinct('goodsLink')
print(len(res))
def repeat():
links = goodsInfo.find()
tmp = set()
for link in links:
if link['goodsLink'] not in tmp:
tmp.add(link['goodsLink'])
else:
# goodsInfo.delete_one({'goodsLink':link['goodsLink']})
print(link)
4.获取MongoDB已存储的数据
import pymongo
def getData(sheetName):
client = pymongo.MongoClient('localhost',27017)
projectDb = client['58project']
sheetObj = projectDb[sheetName]
return sheetObj.find()
5.执行入口主文件,多线程异步执行爬去任务
from getGoodsLinks import getGoodsLink
from multiprocessing import Pool
from getMongoData import getData
from getGoodsInfo import getGoodsinfo
from getGoodsInfo import deleteData
from getGoodsInfo import getLineNum
from getGoodsInfo import repeat
def startSpider(cateLink):
for page in range(1, 101):
if not getGoodsLink(cateLink, str(page)):
continue
# if __name__ == '__main__':
# pool = Pool(processes = 8)
# links = getCateLink()
# pool.map(startSpider,links)
#
# if __name__ == '__main__':
# goodsLink = getData('new_goodsLinks')
# urlPond = list(map(lambda x:x['goodsLink'],goodsLink))
# pool = Pool(processes=4)
# pool.map(getGoodsinfo, urlPond)
#
# if __name__ == '__main__':
# getLineNum()